Реляционная модель данных подразумевает отдельное хранение и возможность независимой обработки данных для каждой сущности.
Вместе с тем, часто возникает потребность собрать данные из нескольких связанных таблиц.
Как правило, сущности (таблицы) связаны друг с другом внешними связями по принципу (primary key — foreign key).
Связи могут быть типа «1 к 1» или «1
ко многим» (с вариантами «1 к 0 или 1», «1 к
0 или более», «1 к 2» и пр).
Связь «многие-ко-многим»
в реляционной модели обеспечивается с помощью дополнительной таблицы связей
(другие названия: Link-таблица, Bridge-таблица, xref-таблица).
В зависимости от характера связей между таблицами, операция соединения может быть:
- внутренним соединением (INNER JOIN). При этом:
- если для описания связи между наборами данных используются корреляционные подзапросы, то такой INNER JOIN называют CROSS APPLY
- если условие соединения отсутствует, то такой INNER JOIN называют “декартовым произведением” (CROSS JOIN, CARTESIAN PRODUCT)
- внешним соединением (OUTER JOIN). Разновидности — LEFT JOIN, RIGHT JOIN, FULL JOIN
- если для описания связи между наборами данных используются корреляционные подзапросы, то такой OUTER JOIN называют OUTER APPLY
Новичку порой трудно разобраться, когда и какой тип джоинов нужно использовать и чем одни из них лучше других.
В этой статье мы попробуем решить разными способами несколько практических задач, отмечая плюсы и минусы каждого решения.
Пример логической модели данных:
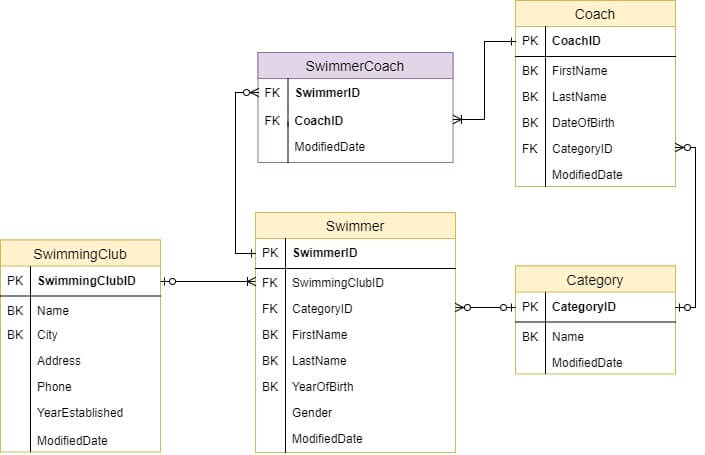
Обратите внимание на характер данных в наших таблицах.
У некоторых спортсменов нет категории, клуба или тренера (возможно, они
неизвестны).
Встречаются
спортсмены, которых ведёт несколько тренеров.
Про одни сущности есть чуть больше информации чем про другие.
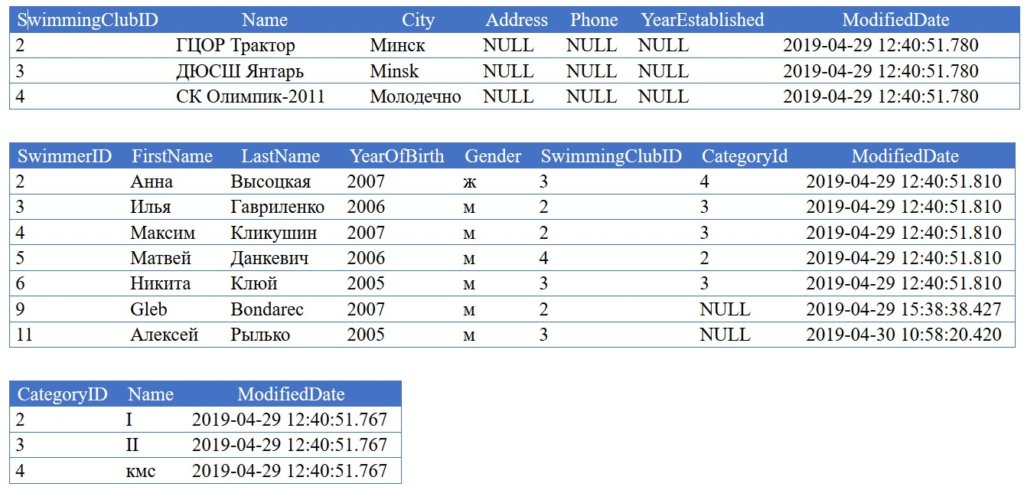
Знакомство с данными.
In [1]:
use tempdb
go
--содержимое таблиц:
select * from dbo.SwimmingClub
select * from dbo.Swimmer
select * from dbo.Category
(3 rows affected)
(7 rows affected)
(3 rows affected)
Out [1]:
Пример #1. Найти всех спортсменов из клуба Янтарь, имеющих II спортивный разряд.
Используя старую нотацию:
In [2]:
use tempdb
go
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc, dbo.Swimmer s, dbo.Category c
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
and s.CategoryID = c.CategoryID
and c.[Name] = N'II'
(1 row affected)
Out [2]:

В этой форме записи WHERE-часть перегружена условиями. Часть из них относятся к логической модели данных (у. 2 и 3), часть – к логике текущей задачи (у. 1 и 4).
В сложных запросах WHERE-часть может стать просто огромной!
Используя новую нотацию:
In [3]:
use tempdb
go
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc
inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID
inner join dbo.Category c on s.CategoryID = c.CategoryID
where sc.[Name] like N'%Янтарь%' and c.[Name] = N'II'
(1 row affected)
Out [3]:

Преимуществом этой формы записи является “разгрузка” WHERE-части от условий, определенных логической моделью данных, при этом четко видно какое из условий используется для реализации связи между какими таблицами.
В сложных запросах новая форма записи позволяет добиться существенно лучшей читаемости кода (а, как увидим позже, еще и лучшей готовности кода к рефакторингу).
Используя CROSS JOIN:
In [4]:
use tempdb
go
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc
cross join dbo.Swimmer s
cross join dbo.Category c
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
and s.CategoryID = c.CategoryID
and c.[Name] = N'II'
(1 row affected)
Out [4]:

Обратите внимание на то, как запрос с CROSS JOIN похож на вариант решения в старой нотации!
На самом деле, ничего удивительного, т. к. логически они выражают один и тот же подход к решению задачи: “все источники данных — в FROM, все условия — в WHERE. При отсутствии условий каждая таблица декартово перемножается с каждой”.
Вообще, вариантов решения задачи много. Но, как можно догадаться, не все они оптимальны;).
Например, порой начинающие программисты для решения первой задачи создают что-то вроде этого:
In [5]:
use tempdb
go
declare @ClubId int,
@ClubCity nvarchar(30),
@ClubName nvarchar(100),
@CategoryId int
set @ClubId = (
select SwimmingClubId from dbo.SwimmingClub where [Name] like N'%Янтарь%'
)
set @ClubCity = (
select City from dbo.SwimmingClub where [Name] like N'%Янтарь%'
)
set @ClubName = (
select [Name] from dbo.SwimmingClub where [Name] like N'%Янтарь%'
)
set @CategoryId = (
select CategoryId from dbo.Category where [Name] = N'II'
)
select SwimmerID, FirstName, LastName, YearOfBirth, Gender,
@ClubName Club, @ClubCity City, N'II' Category
from dbo.Swimmer
where SwimmingClubID = @ClubId and CategoryId = @CategoryId
(1 row affected)
Out [5]:

Идея за этим кодом такова.
Чтобы найти всех спортсменов из клуба Янтарь, имеющих II спортивный разряд, нужно:
- dbo.SwimmingClub
найти код клуба Янтарь (значение внешнего ключа SwimmingClubId)
2. dbo.Category
найти код категории, указывающей на II разряд (значение внешнего ключа CategoryId)
3. dbo.Swimmer
зная эти два значения, найти соответствующих пловцов
Приведенный выше алгоритм “напрашивается” сам собой. Именно поэтому разработчики, далекие от SQL, пишут такие решения.
Недостатком этого подхода являются:
- длинный код (объявление переменных + 5 инструкций SELECT)
- худшая производительность (пять селектов явно медленнее одного)
- неизолированность от конкурирующих транзакций (пока мы рассчитываем значения переменных, данные в любой из таблиц могут быть изменены кем-то другим)
- если есть несколько клубов со словом “Янтарь” в названии, любой из трех первых селектов упадет.
Пример #2. Вывести спортсменов из клуба Янтарь с теми же атрибутами что и выше, но без требования иметь II спортивный разряд.
Используя старую нотацию:
In [6]:
use tempdb
go
--это код с багом! в случае если у спортсмена нет разряда, запись о нем не выводится
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc, dbo.Swimmer s, dbo.Category c
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
and s.CategoryID = c.CategoryID
--подправленный код (один из вариантов)
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City,
(select c.[Name] from dbo.Category c where c.CategoryID = s.CategoryID) Category
from dbo.SwimmingClub sc, dbo.Swimmer s
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
(2 rows affected)
(3 rows affected)
Out [6]:
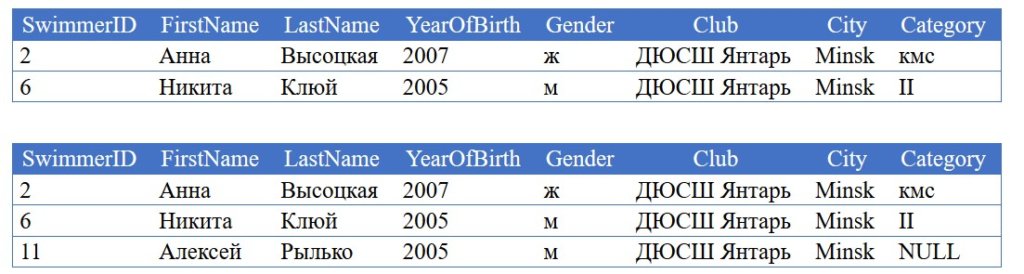
Интуитивно напрашивающееся решение адаптировать старый код под новые требования удалением соответствующего условия не работает!
В старой нотации нужно существенно менять сам код при незначительных изменениях в требованиях.
Используя новую нотацию:
In [7]:
use tempdb
go
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc
inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID
left join dbo.Category c on s.CategoryID = c.CategoryID
where sc.[Name] like N'%Янтарь%'
(3 rows affected)
Out [7]:
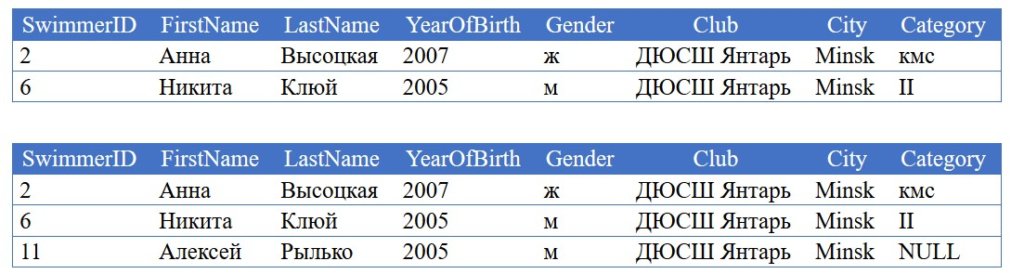
В отличии от старой, после удаления уже ненужного требования, в новой нотации нужно лишь поменять слово inner на left.
Вот и все!
Вариант решения задачи с outer apply:
In [8]:
use tempdb
go
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc
inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID
outer apply (select [Name] from dbo.Category c where c.CategoryID = s.CategoryId) c
where sc.[Name] like N'%Янтарь%'
(3 rows affected)
Out [8]:

Несмотря на запись запроса, похожую на вариант с LEFT JOIN, этот способ не
оптимален из-за имеющегося корреляционного подзапроса.
Последний приводит к тому, что выполнение идет по принципу row—by—row вместо set—based. Логически, мы
выполняем корреляционный подзапрос с внешним параметром s.CategoryId столько раз, сколько строчек в таблице dbo.Swimmer.
Корреляционные запросы существенно ухудшают производительность!
Вариант решения задачи с пользовательской скалярной функцией:
In [9]:
use tempdb
go
create or alter function dbo.fn_GetCategoryName(@CategoryID int)
returns nvarchar
as
begin
return (select [Name] from dbo.Category where CategoryId = @CategoryID)
end
go
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City, dbo.fn_GetCategoryName(s.CategoryId) Category
from dbo.SwimmingClub sc
inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID
where sc.[Name] like N'%Янтарь%'
(3 rows affected)
Out [9]:

Использование пользовательской функции, на первый взгляд, помогает упростить решение задачи и, опять же, масса разработчиков идет этим путем, следуя привычке разбивать сложный функционал на отдельные блоки.
Вместе с тем, это решение в условиях баз данных, скорее всего, еще хуже предыдущего:
- корреляционный подзапрос никуда не делся, он лишь мигрировал в тело функции
- в ходе выполнения запроса функция будет вызвана множество раз, что негативно влияет на производительность (из-за особенностей работы СУБД и интерпретатора языка SQL)
- для решения одной конкретной задачи понадобилось создать дополнительный постоянный объект БД – пользовательскую скалярную функцию.
Если пользоваться таким подходом постоянно, то скоро БД будет завалена множеством непонятных программных объектов!
Вывод.
В рассмотренных примерах победителем стал запрос, созданный в новой нотации без использования корреляционных подзапросов. Он максимально читабельный, легко меняется в случае изменения требований, производительный и не требует создания дополнительных объектов в БД.
Автор материала – Тимофей Гавриленко, преподаватель Тренинг центра ISsoft.

Образование: окончил с отличием математический факультет Гомельского Государственного Университета им. Франциска Скорины.
Microsoft Certified Professional (70-464, 70-465).
Работа: c 2011 года работает в компании ISsoft (ETL/BI Developer, Release Manager, Data Analyst/Architect, SQL Training Manager), на протяжении 10 лет до этого выступал как Sysadmin, DBA, Software Engineer.
В свободное время ведет бесплатные образовательные курсы для детей и взрослых, желающих повысить свой уровень компьютерной грамотности и переквалифицироваться в IT-специалиста.






