
Пример логической модели данных:
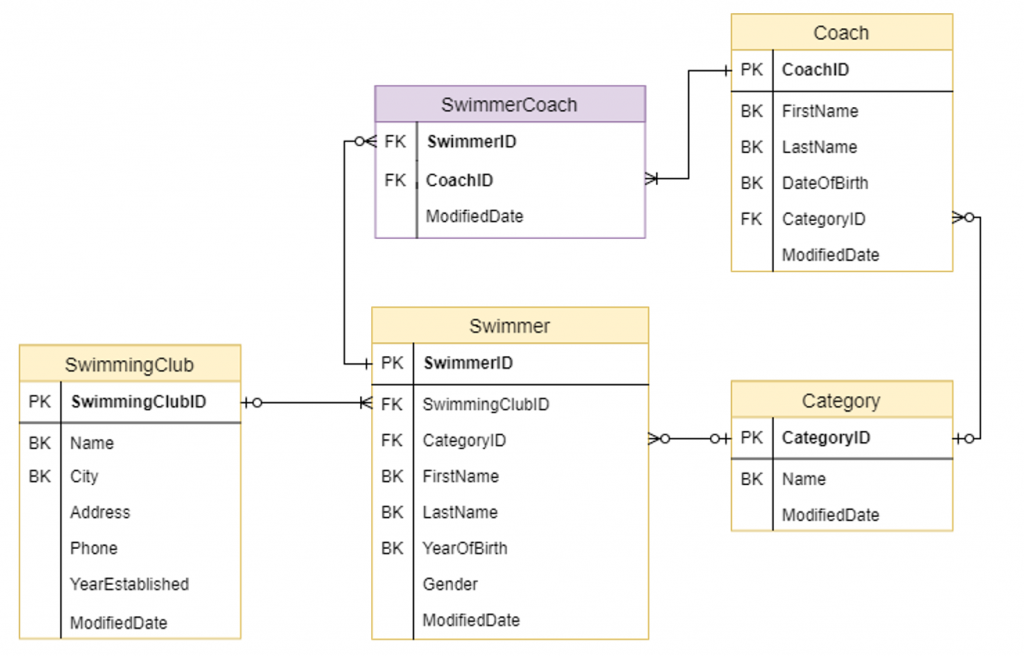
«Насетапим» немного данных.
У некоторых спортсменов нет категории, клуба или тренера (или они неизвестны).
Встречаются спортсмены, которых ведёт несколько тренеров.
Про одни сущности есть чуть больше информации, чем про другие.
Сначала удалим старые данные.
Ниже не очень хороший код:
- возможны нарушения целостности при отсутствии внешних ключей или исключения при их присутствии (из-за использования truncate table);
- используется схема по умолчанию, что чревато возможным удалением «чужих» данных (в одноименных таблицах, но другой схеме).
Вариант №1 (truncate):
In [0]:
use tempdb
go
truncate table SwimmerCoach
truncate table SwimmingClub
truncate table Swimmer
truncate table Category
truncate table Coach
go
Вариант №2 (delete):
In [1]:
use tempdb
go
--clear first tables having no dependencies on others
delete from dbo.SwimmerCoach
go
delete from dbo.SwimmingClub
go
delete from dbo.Swimmer
go
delete from dbo.Category
go
delete from dbo.Coach
go
Вариант выше обладает недостатками: он медленный, привязанный к текущему набору таблиц и построен на знании текущих зависимостей между таблицами.
А что, если мы …
- хотим минимизировать число проблем, связанных с возможными изменениями в схеме?
- хотим иметь право выбора в отношении того, удалять ли «старые» данные перед вставкой новых?
- хотим выбирать из каких таблиц удалять данные?
- и делать это легко и, по возможности, без проблем с производительностью (то есть быстро)?
Хранимка ниже упрощает процесс очистки таблиц, причем позволяет запустить его в “отладочном” режиме, генерируя весь необходимый код с выводом последнего в окно стандартного вывода (на экран). Удаление данных – вещь серьезная и, в общем случае, неплохо иметь возможность контролировать этот процесс.
Предлагаем читателю самому разобраться с алгоритмом хранимой процедуры.
Обратим внимание лишь на то, что по умолчанию действует режим отладки (значение по умолчанию 1 параметра @debug), благодаря чему ничего не удаляется, но генерируется информативный набор SQL-команд с комментариями.
Вариант №3 (framework-procedure):
In [2]:
use tempdb
go
if not exists(select 1 from INFORMATION_SCHEMA.SCHEMATA where [SCHEMA_NAME] = 'admin')
exec('create schema [admin]')
go
if object_id('[admin].usp_ClearTables', 'P') is not null
drop procedure [admin].usp_ClearTables
go
---------------------------------------------------------------------------------------
-- procedure removes data from given list of tables (input json-parameter)
-- created by: Timofey Gavrilenko
-- created date: 4/23/2019
-- sample call:
-- exec [admin].usp_ClearTables N'["dbo.SwimmerCoach", "dbo.SwimmingClub", "dbo.Swimmer", "dbo.Category", "dbo.Coach"]'
---------------------------------------------------------------------------------------
create procedure [admin].usp_ClearTables
@list nvarchar(max) = null,
@debug tinyint = 1
as
begin
set nocount on
if @list is null
return
--table to store sql scripts
create table #scripts
(
id int not null identity primary key,
[object_id] int not null,
[table_name] sysname not null,
add_sql nvarchar(max),
drop_sql nvarchar(max),
truncate_sql nvarchar(max)
)
--get table list from input json
create table #tables
(
id int not null identity primary key,
[table_name] sysname not null,
[object_id] int
)
insert into #tables([table_name], [object_id])
select [value],
object_id([value])
from openjson(@list)
--get drop-scripts
insert into #scripts ([object_id], [table_name], drop_sql)
select t.[object_id],
t.[name],
formatmessage(
N'alter table %s.%s drop constraint %s',
quotename(s.[name]),
quotename(t.[name]),
quotename(fk.[name])
)
from sys.foreign_keys fk
join sys.tables t on fk.[parent_object_id] = t.[object_id]
join sys.schemas s on s.[schema_id] = t.[schema_id]
join #tables tl on tl.[object_id] = t.[object_id]
order by t.[object_id]
--get add-scripts
update s
set add_sql = q.add_sql,
truncate_sql = case
when exists(
select 1 from #scripts
where id > s.id and
[table_name] = s.[table_name]
)
then null
else formatmessage(
N'truncate table %s.%s',
quotename(q.[schema_name]),
quotename(q.[table_name])
)
end
from #scripts s
join (
select
t2.[object_id],
s2.[name] [schema_name],
t2.[name] [table_name],
formatmessage(
N'alter table %s.%s add constraint %s foreign key (%s) references %s.%s (%s)',
--alter table
quotename(s2.[name]),
quotename(t2.[name]),
--add constraint
quotename(fk.[name]),
--foreign key
stuff(
(
select ',' + quotename(c.[name])
from sys.columns as c
join sys.foreign_key_columns fkc on fkc.parent_column_id = c.column_id and
fkc.parent_object_id = c.[object_id]
where fkc.constraint_object_id = fk.[object_id]
order by fkc.constraint_column_id
for xml path(N''), type
).value(N'.[1]', N'nvarchar(max)'),
1, 1, N''
),
--references
quotename(s1.[name]),
quotename(t1.[name]),
stuff(
(
select ',' + quotename(c.[name])
from sys.columns as c
join sys.foreign_key_columns fkc on fkc.referenced_column_id = c.column_id and
fkc.referenced_object_id = c.[object_id]
where fkc.constraint_object_id = fk.[object_id]
order by fkc.constraint_column_id
for xml path(N''), type
).value(N'.[1]', N'nvarchar(max)'),
1, 1, N''
)
) add_sql
from sys.foreign_keys fk
join sys.tables t1 on fk.referenced_object_id = t1.[object_id]
join sys.schemas s1 on t1.[schema_id] = s1.[schema_id]
join sys.tables t2 on fk.parent_object_id = t2.[object_id]
join sys.schemas s2 on t2.[schema_id] = s2.[schema_id]
) q on q.[object_id] = s.[object_id]
--get list of sql scripts to execute in right order
create table #scripts_in_order
(
id int not null identity primary key,
script nvarchar(max) not null
)
insert into #scripts_in_order(script)
select N'-- pass @debug = 0 for executing scripts'
union all
select N'-- drop all fk constraints...'
union all
select drop_sql from #scripts
union all
select N'-- truncate all tables...'
union all
select truncate_sql from #scripts where truncate_sql is not null
union all
select formatmessage(N'truncate table %s', t.table_name)
from #tables t
left join #scripts s on t.[object_id] = s.[object_id]
where s.[object_id] is null
union all
select N'-- recreate fk constraints...'
union all
select add_sql from #scripts
union all
select N'-- done!'
--run drop constraint, truncate table, add constraint scripts
declare @id int = 1,
@maxid int = @@rowcount,
@sql nvarchar(max)
begin try
begin tran
while @id <= @maxid
begin
select @sql = script
from #scripts_in_order
where id = @id
if @debug <> 0
print @sql
else
execute(@sql)
set @id +=1
end --while
commit
end try
begin catch
print 'Oops. There were issues when executing [admin].[usp_ClearTables]'
rollback
end catch
end
go
Теперь можно писать скрипт на вставку данных
Ниже не очень хороший код:
- всегда удаляются имеющиеся данные (а, возможно, мы не всегда этого хотим!);
- привязанность к текущей схеме данных, код слишком “низкоуровневый”;
- хардкод в отношении данных, значений primary и foreign ключей.
В случае любых изменений схемы данных (таких, как нормализация или переименование атрибутов) или самих данных (например, добавление дополнительных записей) код ниже придется переписать.
In [3]:
use tempdb
go
--очистка данных
exec [admin].usp_ClearTables N'["dbo.SwimmerCoach",
"dbo.SwimmingClub",
"dbo.Swimmer",
"dbo.Category",
"dbo.Coach"]',
@debug = 0
go
insert into dbo.SwimmingClub([Name], City)
values (N'ГЦОР Трактор', N'Минск'),
(N'ДЮСШ Янтарь', N'Минск'),
(N'СК Олимпик-2011', N'Молодечно')
insert into dbo.Category([Name])
values (N'1 юн'),
(N'III'),
(N'II'),
(N'I'),
(N'кмс'),
(N'тренер 1 кат')
insert into dbo.Swimmer(SwimmingClubID, CategoryId, FirstName, LastName, YearOfBirth, Gender)
values (1, 3, N'Илья', N'Гавриленко', 2006, N'м'),
(1, 3, N'Максим', N'Кликушин', 2007, N'м'),
(2, 5, N'Анна', N'Высоцкая', 2006, N'ж'),
(2, 3, N'Никита', N'Клюй', 2005, N'м'),
(3, 4, N'Матвей', N'Данкевич', 2006, N'м')
insert into dbo.Coach(FirstName, LastName)
values (N'Алла', N'Усенок'),
(N'Виталий', N'Барташевич'),
(N'Евгения', N'Жукова')
insert into dbo.SwimmerCoach(SwimmerID, CoachID)
values (1, 1),
(1, 2),
(2, 1),
(2, 2),
(3, 3)
Попробуем сделать вставку данных более гибкой.
Идея:
- вставку осуществлять с помощью специальной хранимой процедуры;
- данные для вставки передавать в процедуру извне;
- помимо данных, передавать флаг очищать ли уже имеющиеся данные.
Передавать мы будем сериализованные данные с помощью JSON-параметра, что очень удобно для интеграции нескольких частей сложной программной системы. Так, например, мы можем вызывать хранимую процедуру после конвертации любых исходных форматов данных, в тот JSON, что она принимает на вход, или даже просто сериализовав в режиме реального времени объекты приложения, работающего с этой БД. JSON с данными в этом случае будет служить интерфейсом между приложением и БД.
В первую очередь, надо продумать структуру JSON.
Чтобы сделать это, нужно заглянуть в возможную объектную модель приложения или представить себе альтернативную, документ-ориентированную модель данных (эквивалентную текущей реляционной модели).
Допустим, в ходе дизайна схемы JSON, у нас получилось что-то такое (обратите внимание, наш случай довольно прост, зачастую мы не сможем обойтись лишь одним документом):
[
{
"FirstName": "Илья",
"LastName": "Гавриленко",
"YearOfBirth": 2006,
"Gender": "м",
"Club": {
"Name": "ГЦОР Трактор",
"City": "Минск"
},
"Category": "II",
"Coach": [
{"FirstName": "Алла", "LastName": "Усенок"},
{"FirstName": "Виталий", "LastName": "Барташевич"}
]
},
{
"FirstName": "Максим",
"LastName": "Кликушин",
"YearOfBirth": 2007,
"Gender": "м",
"Club": {
"Name": "ГЦОР Трактор",
"City": "Минск"
},
"Category": "II",
"Coach": [
{"FirstName": "Алла", "LastName": "Усенок"},
{"FirstName": "Виталий", "LastName": "Барташевич"}
]
},
{
"FirstName": "Анна",
"LastName": "Высоцкая",
"YearOfBirth": 2006,
"Gender": "ж",
"Club": {
"Name": "ДЮСШ Янтарь",
"City": "Минск"
},
"Category": "кмс",
"Coach": [
{"FirstName": "Евгения", "LastName": "Жукова"}
]
},
{
"FirstName": "Никита",
"LastName": "Клюй",
"YearOfBirth": 2005,
"Gender": "м",
"Club": {
"Name": "ДЮСШ Янтарь",
"City": "Минск"
},
"Category": "II"
},
{
"FirstName": "Матвей",
"LastName": "Данкевич",
"YearOfBirth": 2006,
"Gender": "м",
"Club": {
"Name": "СК Олимпик-2011",
"City": "Молодечно"
},
"Category": "I"
}
]
Теперь нам нужно создать процедуру импорта данных, способную разобрать подобный JSON и вставить данные в множество связанных между собой реляционных таблиц.
Можно создать одну большую процедуру импорта, выполняющую всю работу.
Минусами этого подхода будут:
- привязанность одновременно и к схеме реляционной БД, и к схеме JSON;
- высокая сложность одного программного объекта и необходимость его рефакторинга при любых изменениях требований или багах;
- отсутствие возможности «тонкого тюнинга» и вставки более гранулированных данных (например, клубы или тренеры без привязки к спортсменам);
- трудности распараллеливания работы над несколькими сущностями.
Альтернативным (и, вероятно, предпочтительным в общем случае вариантом) будет создание “мелких” хранимых процедур на вставку спортсменов, тренеров, клубов, категорий и одной управляющей процедуры, парсящей входящий “большой” JSON и вызывающей в нужном порядке эти “мелкие” процедуры узкого назначения.
В нашем случае мы реализуем первый вариант.
In [3]:
use tempdb
go
if object_id('dbo.usp_ImportSwimmersData', 'P') is not null
drop procedure dbo.usp_ImportSwimmersData
go
---------------------------------------------------------------------------------------
-- procedure imports data from incoming JSON-parameter into a number of relation tables
-- created by: Timofey Gavrilenko
-- created date: 4/26/2019
-- sample call:
-- exec dbo.usp_ImportSwimmersData @parameters =
--N'
--[
-- {
-- "FirstName": "Илья",
-- "LastName": "Гавриленко",
-- "YearOfBirth": 2006,
-- "Gender": "м",
-- "Club": {
-- "Name": "ГЦОР Трактор",
-- "City": "Минск"
-- },
-- "Category": "II",
-- "Coach": [
-- {"FirstName": "Алла", "LastName": "Усенок"},
-- {"FirstName": "Виталий", "LastName": "Барташевич"}
-- ]
-- }
--]'
---------------------------------------------------------------------------------------
create procedure dbo.usp_ImportSwimmersData
@parameters nvarchar(max) = null
as
begin
set nocount on
--if @parameters is null
-- return
create table #Swimmer
(
id int not null identity primary key,
FirstName nvarchar(20) not null,
LastName nvarchar(30) not null,
YearOfBirth smallint not null,
Gender nchar(1) not null,
Category nvarchar(20),
Club nvarchar(max),
Coach nvarchar(max)
)
create table #Club
(
id int not null identity primary key,
[Name] nvarchar(100) not null,
City nvarchar(30) not null,
[Address] nvarchar(200),
Phone nvarchar(15),
YearEstablished smallint,
)
create table #Coach
(
id int not null identity primary key,
FirstName nvarchar(20) not null,
LastName nvarchar(30) not null,
DateOfBirth date,
Category nvarchar(20)
)
--get list of swimmers from json
insert into #Swimmer(FirstName, LastName, YearOfBirth, Gender, Category, Club, Coach)
select *
from openjson(@parameters)
with
(
FirstName nvarchar(20) N'$.FirstName',
LastName nvarchar(30) N'$.LastName',
YearOfBirth smallint N'$.YearOfBirth',
Gender nchar(1) N'$.Gender',
Category nvarchar(20) N'$.Category',
Club nvarchar(max) N'$.Club' as json,
Coach nvarchar(max) N'$.Coach' as json
) js
--get list of clubs from json
insert into #Club([Name], City, [Address], Phone, YearEstablished)
select distinct jc.[Name], jc.City, jc.[Address], jc.Phone, jc.YearEstablished
from #Swimmer s
cross apply openjson(s.Club)
with
(
[Name] nvarchar(100) N'$.Name',
City nvarchar(30) N'$.City',
[Address] nvarchar(200) N'$.Address',
Phone nvarchar(15) N'$.Phone',
YearEstablished smallint N'$.YearEstablished'
) jc
--get list of coaches from json
insert into #Coach(FirstName, LastName, DateOfBirth, Category)
select distinct jc.FirstName, jc.LastName, jc.DateOfBirth, jc.Category
from #Swimmer s
cross apply openjson(s.Coach)
with
(
FirstName nvarchar(20) N'$.FirstName',
LastName nvarchar(30) N'$.LastName',
DateOfBirth date N'$.DateOfBirth',
Category nvarchar(20) N'$.Category'
) jc
--let's first insert what is easy (data without foreign keys)
--insert new categories
insert into dbo.Category ([Name])
select jc.[Name]
from
(
select Category as [Name] from #Swimmer
union
select Category from #Coach
) jc
left join dbo.Category c on jc.[Name] = c.[Name]
where c.CategoryID is null and
jc.[Name] is not null
--below we'll use natural/alternative keys from JSON data to get ids (foreign keys)
--insert new clubs
insert into dbo.SwimmingClub ([Name], City, [Address], Phone, YearEstablished)
select jsc.[Name], jsc.City, jsc.[Address], jsc.Phone, jsc.YearEstablished
from
(
select distinct [Name], City, [Address], Phone, YearEstablished
from #Club
) jsc
left join dbo.SwimmingClub sc on jsc.[Name] = sc.[Name] and
jsc.City = sc.City
where sc.SwimmingClubID is null
--insert new coaches
insert into dbo.Coach (FirstName, LastName, DateOfBirth, CategoryID)
select jc.FirstName, jc.LastName, jc.DateOfBirth, jc.CategoryID
from
(
--dbo.Coach table has dependency on dbo.Category (not required however)
select distinct FirstName, LastName, DateOfBirth, c.CategoryID
from #Coach
left join dbo.Category c on #Coach.Category = c.[Name]
) jc
left join dbo.Coach c on jc.FirstName = c.FirstName and
jc.LastName = c.LastName
where c.CoachID is null
--insert new swimmers
insert into dbo.Swimmer (FirstName, LastName, YearOfBirth, Gender, SwimmingClubID, CategoryID)
select js.FirstName, js.LastName, js.YearOfBirth, js.Gender, js.SwimmingClubID, js.CategoryID
from
(
--dbo.Swimmer table has dependency on dbo.Club (not required)
select distinct FirstName, LastName, YearOfBirth, Gender, sc.SwimmingClubID, c.CategoryID
from #Swimmer s
left join dbo.Category c on s.Category = c.[Name]
outer apply openjson(s.Club)
with
(
[Name] nvarchar(100) N'$.Name',
City nvarchar(30) N'$.City'
) jsc
left join dbo.SwimmingClub sc on jsc.[Name] = sc.[Name] and
jsc.City = sc.City
) js
left join dbo.Swimmer s on js.FirstName = s.FirstName and
js.LastName = s.LastName and
js.YearOfBirth = s.YearOfBirth and
js.Gender = s.Gender
where s.SwimmerID is null
--insert new relationships between swimmers and coaches
insert into dbo.SwimmerCoach (SwimmerID, CoachID)
select s.SwimmerID, c.CoachID
from #Swimmer js
join dbo.Swimmer s on js.FirstName = s.FirstName and
js.LastName = s.LastName and
js.YearOfBirth = s.YearOfBirth and
js.Gender = s.Gender
cross apply openjson(js.Coach)
with
(
FirstName nvarchar(20) N'$.FirstName',
LastName nvarchar(30) N'$.LastName'
) jc
join dbo.Coach c on jc.FirstName = c.FirstName and
jc.LastName = c.LastName
left join dbo.SwimmerCoach sc on s.SwimmerID = sc.SwimmerID and
c.CoachID = sc.CoachID
where sc.SwimmerID is null and sc.CoachID is null
end
go
Теперь мы можем добиться инкапсулирования данных и отделения backend-а в виде БД от приложения со всеми вытекающими “плюшками”:
- возможностью внесения изменений, как на стороне приложения, так и на стороне БД, до тех пор, пока сохраняется формат интерфейса данных (JSON-схема);
- возможностью наполнять БД данными из любых источников, если мы в состоянии предварительно сериализовать их в JSON той схемы, что принимает на вход хранимая процедура;
- отделением модели БД от самих данных. Данные можно вставлять несколькими процессами в параллели, в любой последовательности, в том числе в уже непустую БД;
- при желании, можно создать вспомогательное приложение генерации данных в формате JSON с заданными параметрами и автоматизировать наполнение БД на тестовом сервере (тема отдельной статьи).
Автор материала – Тимофей Гавриленко, преподаватель Тренинг-центра ISsoft.

Образование: окончил с отличием математический факультет Гомельского Государственного Университета им. Франциска Скорины.
Microsoft Certified Professional (70-464, 70-465).
Работа: c 2011 года работает в компании ISsoft (ETL/BI Developer, Release Manager, Data Analyst/Architect, SQL Training Manager), на протяжении 10 лет до этого выступал как Sysadmin, DBA, Software Engineer.
В свободное время ведет бесплатные образовательные курсы для детей и взрослых, желающих повысить свой уровень компьютерной грамотности и переквалифицироваться в IT-специалиста.






