
* Все, использованные в статье документы, включая код в виде SQL-ноутбука .ipynb, можно получить по ссылке внизу документа.
ETL – общий термин для всех процессов миграции данных из одного источника в другой (другие связанные с этим термины – экспорт, импорт, конвертация данных, парсинг файлов, web-scrapping и пр.)
Типичные этапы ETL-процесса:
- извлечение данных из источника (файл, БД, веб-страница и пр);
- очистка данных (приведение разнородных данных к единому формату, удаление лишнего, устранение недочетов и пр);
- обогащение (применение алгоритмов или внешних источников для получения новых данных, связанных с обрабатываемыми данными);
- трансформирование;
- загрузка (интеграция в единую целевую модель).
Сложные ETL-процессы, как правило, разбиваются на цепочку более простых.
Рассмотрим частный случай импорта данных из внешнего файла. Например, из Excel или csv.
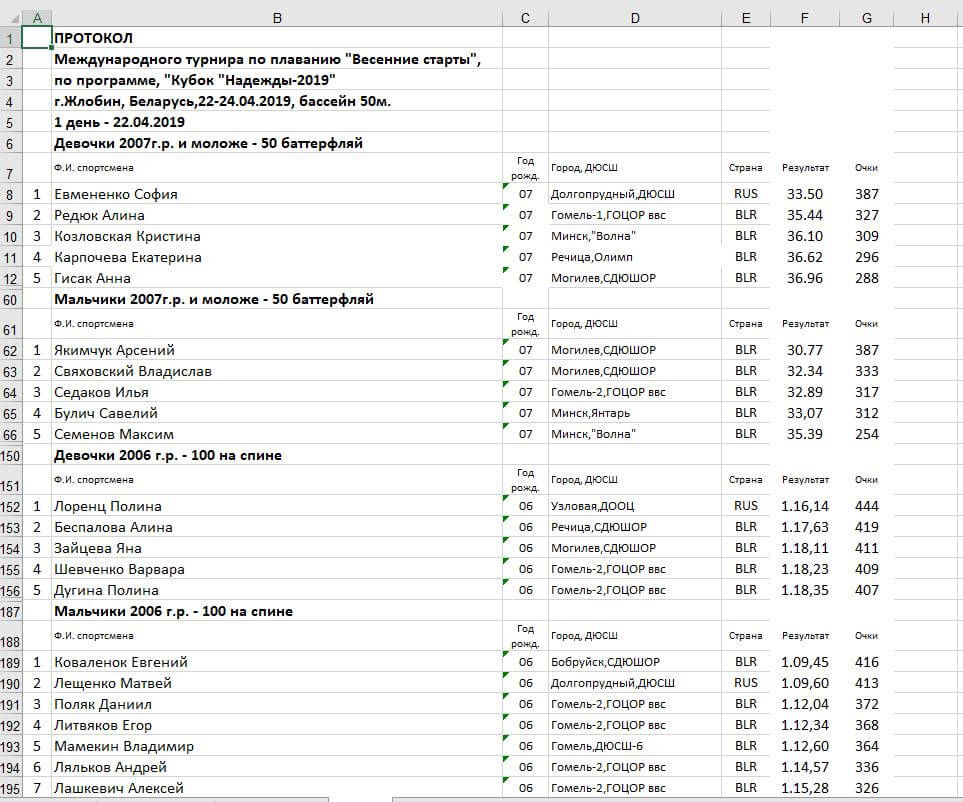
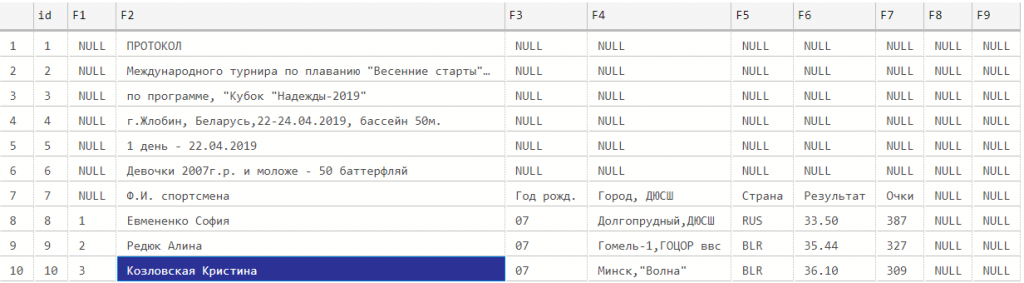
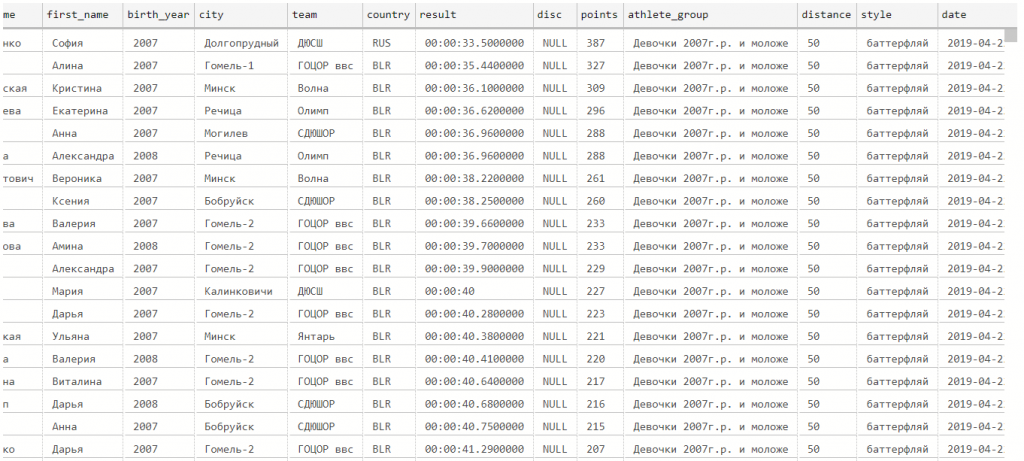
Образец файла с исходными данными (протокол проведенных соревнований по плаванию):
Модель данных в целевой БД:
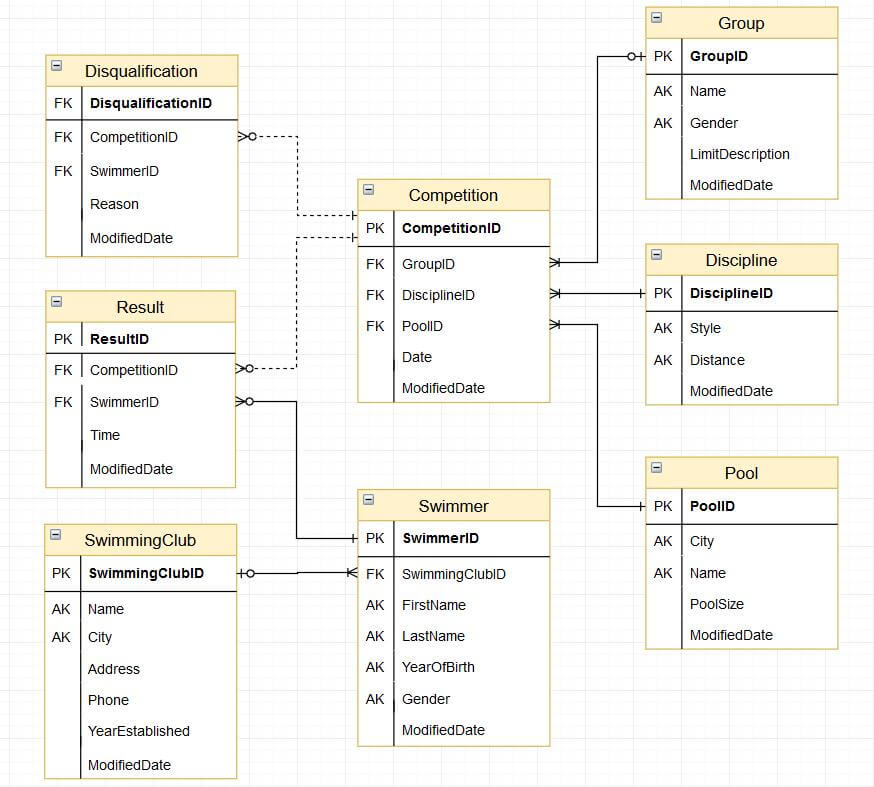
Загрузка данных в модель выше довольно сложная задача, учитывая, что исходные данные находятся в неструктурированном виде. В данной статье мы ограничимся подготовкой последних для загрузки в стейджинговую (т.е. промежуточную с точки зрения целевой модели) таблицу.
Промежуточная таблица в данном случае позволяет сконцентрироваться на процессе первоначальной подготовки данных и переносе их из внешнего неструктурированного источника (см. скриншот выше) во внутренний, очищенный и удобный с точки зрения БД для последующей работы формат.
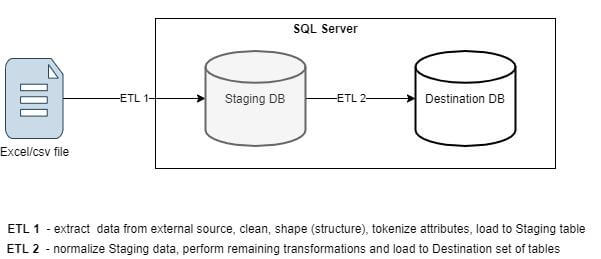
Архитектура ETL (мы концентрируемся на ETL 1):
Для определения возможной схемы стейджинговой таблицы проведем первичный data profiling, определив:
- метрики исходных данных (список атрибутов, их типы, длину строковых полей, null/not null, потенциальный ключ, степень соответствия целевым атрибутам и пр);
- аномалии (грязные или отсутствующие данные, множественные значения и пр);
- возможный способ осуществления парсинга.
Требования к Staging-ETL (v1.0):

Глядя на исходные данные, приходим к выводу что в них присутствуют множественные значения. Мы не будем готовы загрузить такие данные в целевые таблицы (например, строки Фамилия+Имя, Клуб+Город, Группа+Длина дистанции+Стиль плавания).
Нужно детальное сравнение исходных данных с целевыми атрибутами и уточнение требований.
Уточненные требования:
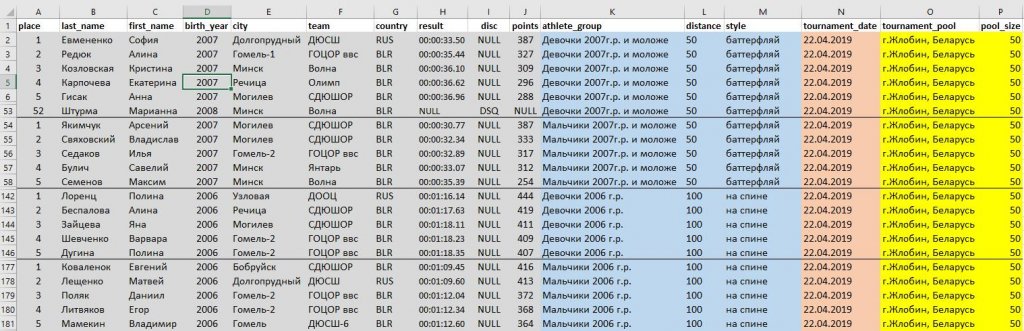
Создадим рабочую таблицу для загрузки “сырых” исходных данных.
Фактически, мы будем создавать ELT (Extract-Load-Transform) а не ETL (Extract-Transform-Load) код. Другими словами, все трансформации и очистку данных мы будем делать ПОСЛЕ загрузки сырых данных в БД.
In [0]:
use tempdb
go
drop table if exists dbo.stg_competitions
go
create table dbo.stg_competitions
(
id int not null identity,
F1 nvarchar(255) null,
F2 nvarchar(255) null,
F3 nvarchar(255) null,
F4 nvarchar(255) null,
F5 nvarchar(255) null,
F6 nvarchar(255) null,
F7 nvarchar(255) null,
F8 nvarchar(255) null,
F9 nvarchar(255) null,
constraint PK_stg_Competitions primary key
(
id
)
)
go
Будем полагать исходные данные находятся в текстовом файле формата csv.
Если, изначально данные находятся в Excel, конверсию в csv можно предварительно сделать программно или средствами самого Excel.
Грузим данные в рабочую таблицу:
In [1]:
truncate table dbo.stg_Competitions
bulk insert dbo.stg_competitions
from 'c:/temp/итоговый протокол.csv'
with (
format = 'csv',
codepage = 65001,
formatfile = 'c:/temp/stg_competitions.fmt',
--firstrow = 1,
fieldterminator = ','
)
go
select top 10 * from dbo.stg_Competitions
Commands completed successfully.
(1470 rows affected)
(5 rows affected)
Out[1]:
Альтернативно, ту же задачу можно было сделать с помощью мастера импорта данных или с помощью
- openrowset:
select *
from openrowset(
bulk 'c:/temp/итоговый протокол.csv',
formatfile = 'c:/temp/stg_competitions.fmt',
format='csv',
codepage='65001'
) a
- bcp:
bcp testdb.dbo.stg_Competitions format nul -f ./stg_Competitions.fmt -S 127.0.0.1 -U SA -P "password"
bcp stg_Competitions in /home/gavrilenkotimofey/Соревнования.csv -f ./stg_Competitions.fmt -S localhost -U sa -P "password" -d testdb
Попробуем решить задачу одним запросом SELECT, разбив его на ряд CTE-модулей
In [1]:
--Шаг 1. Попытка извлечь из данных список возрастных групп (одна группа на одну соревновательную дисциплину)
--Ищем строку с результатом спортсмена, занявшего первое место. Двумя строками выше в колонке F2 находится название группы:
;with cte_list_of_group_discipline
as
(
select c.id,
c.F2 as group_discipline
from dbo.stg_Competitions c
join dbo.stg_Competitions c2 on c.id+2 = c2.id
where c2.F1 = '1'
)
select * from cte_list_of_group_discipline
(30 rows affected)
Out[1]:
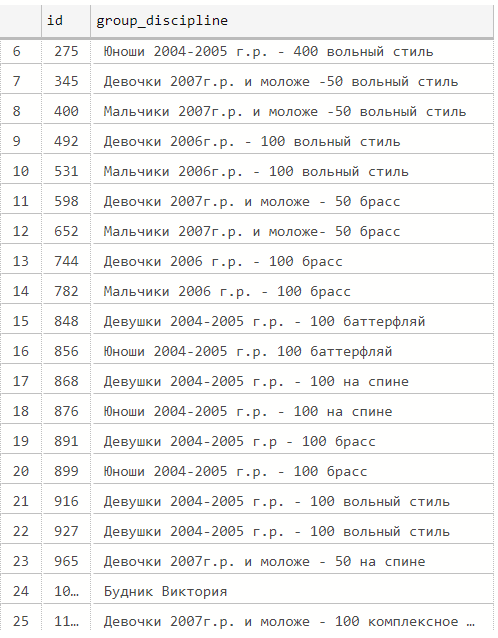
Внимательно проанализировав полученный результат, мы находим признак грязных данных (Будник Виктория в названии группы).
После выяснения причины оказывается, в исходных данных нарушен общий порядок “Название группы-Строка заголовка-Данные” (см. ниже фрагмент исходного файла). В данном случае ниже названия группы “Мальчики 2007г.р. и моложе — 50 на спине” отсутствует строка заголовка, а сразу идут результатов спортсменов, поэтому название группы находится не как обычно на 2 строки выше первого места, а на одну строку.

Нужна доработка кода выше под эту особенность и строго продуманный подход к тому, как мы будем парсить исходные данные. Попытка выработать этот самый строгий подход дана в размеченном скриншоте ниже.
Предварительный анализ «сырых» данных
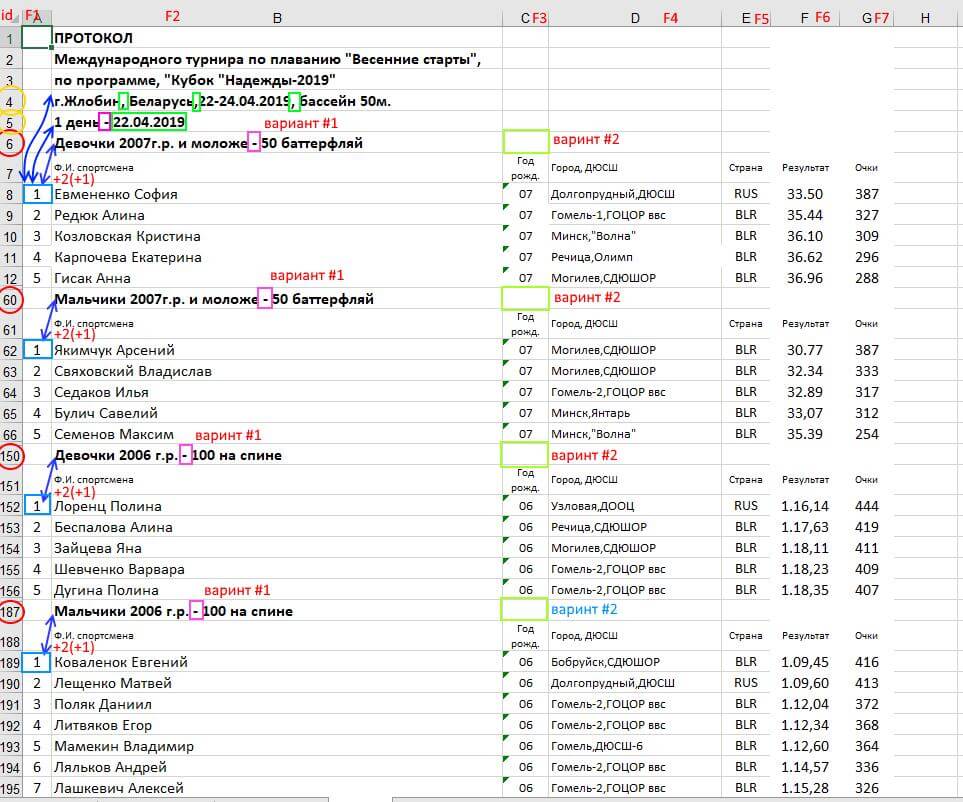
In [4]:
;with cte_list_of_group_discipline
as
(
select c.id,
c.F2 as group_discipline
from dbo.stg_Competitions c
join dbo.stg_Competitions c1 on c.id+1 = c1.id
join dbo.stg_Competitions c2 on c.id+2 = c2.id
where (c1.F1 = '1' and /*(charindex('-', c.F2)<>0))*/ c.F3 is null) or
(c2.F1 = '1' and /*(charindex('-', c.F2)<>0))*/ c.F3 is null)
)
select * from cte_list_of_group_discipline
(30 rows affected)
Out[4]:

Определение списка соревновательных дней:
In [5]:
;with cte_list_of_competition_days
as
(
select c.id,
c.F2 as group_discipline
from dbo.stg_Competitions c
join dbo.stg_Competitions c3 on c.id+3 = c3.id
where c3.F1 = '1' and (charindex('-', c.F2)<>0)
)
select * from cte_list_of_competition_days
(2 rows affected)
Out[5]:

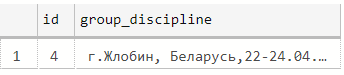
Определение места проведения соревнования:
In [7]:
;with cte_competition_info
as
(
select c.id,
c.F2 as group_discipline
from dbo.stg_Competitions c
join dbo.stg_Competitions c3 on c.id+4 = c3.id
where c3.F1 = '1' and (charindex('-', c.F2)<>0)
)
select * from cte_competition_info
(1 row affected)
Out[7]:
«Разворот» строк с найденными значениями в столбцы:
In [6]:
;with cte_trim_fields
as
(
select ltrim(rtrim(F1)) as F1,
ltrim(rtrim(F2)) as F2,
ltrim(rtrim(F3)) as F3,
ltrim(rtrim(F4)) as F4,
ltrim(rtrim(F5)) as F5,
ltrim(rtrim(F6)) as F6,
ltrim(rtrim(F7)) as F7,
id
from stg_Competitions
),
cte_list_of_group_discipline
as
(
select c.id,
c.F2 as group_discipline
from cte_trim_fields c
join cte_trim_fields c1 on c.id+1 = c1.id
join cte_trim_fields c2 on c.id+2 = c2.id
where (c1.F1 = '1' and (charindex('-', c.F2)<>0)) or
(c2.F1 = '1' and (charindex('-', c.F2)<>0))
),
cte_list_of_ranges
as
(
select id start_id,
lead(id) over(order by id) end_id
from cte_list_of_group_discipline
),
cte_pivot
as
(
select c.*, gd.group_discipline
from cte_trim_fields c
join cte_list_of_ranges rr on c.id between rr.start_id and case when rr.end_id-1 is not null then rr.end_id-1 else (select count(1) from stg_Competitions) end
join cte_list_of_group_discipline gd on gd.id = rr.start_id
)
select top 20 * from cte_pivot
(100 rows affected)
Out[6]:
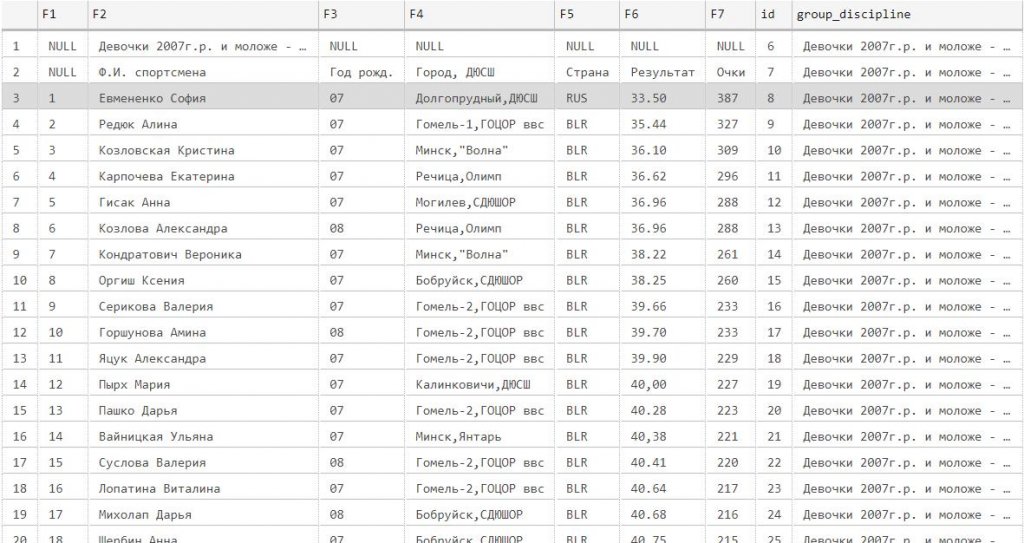
Мы приблизились к выполнению требований.
Теперь сконцентрируемся на разбиении множественных атрибутов на атомарные значения.
Попробуем разбить Фамилию Имя:
In [3]:
declare @name varchar(100) = N'Евмененко София'
select @name as full_name,
iif(charindex(' ', @name)<>0, left(@name, charindex(' ', @name) - 1), @name) as last_name,
iif(charindex(' ', @name)<>0, right(@name, len(@name) - charindex(' ', @name)), null) as first_name
(1 row affected)
Out[3]:

Проверим корректно ли происходит разбиение на всем множестве записей (у всех таких записей значение в колонке F1 не пусто):
In [7]:
-- результаты на первый взгляд положительны.
--select F2,
-- iif(charindex(' ', F2)<>0, left(F2, charindex(' ', F2) - 1), F2) as last_name,
-- iif(charindex(' ', F2)<>0, right(F2, len(F2) - charindex(' ', F2)), null) as first_name
--from dbo.stg_Competitions
--where F1 is not null
-- но лучше убедиться убедиться лишний раз, потратив немного больше времени...
select distinct iif(charindex(' ', F2)<>0, left(F2, charindex(' ', F2) - 1), F2) as last_name
from dbo.stg_Competitions
where F1 is not null
select distinct iif(charindex(' ', F2)<>0, right(F2, len(F2) - charindex(' ', F2)), null) as first_name
from dbo.stg_Competitions
where F1 is not null
(324 rows affected)
(106 rows affected)
Out[7]:
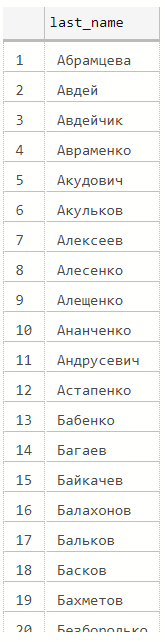
Out[7]:
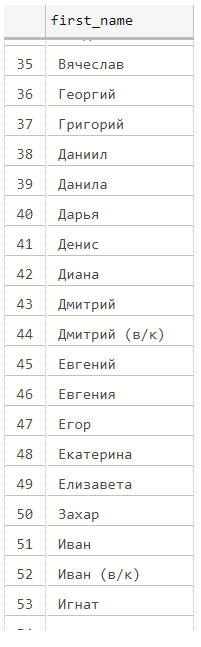
Время на data profiling было потрачено не зря! Порой имя спортсмена содержит символы (в/к), что, вероятнее всего, означает что он участвовал в соревновании вне конкурса.

Для того чтобы загрузить лишь имя спортсмена, в поле first_name нужно взять первое слово (в случае если их несколько):
In [8]:
select distinct left(first_name, len(first_name) - charindex(' ', reverse(first_name))) first_name
from (
select distinct iif(charindex(' ', F2)<>0, right(F2, len(F2) - charindex(' ', F2)), null) as first_name
from dbo.stg_Competitions
where F1 is not null
) q
(99 rows affected)
Out[8]:
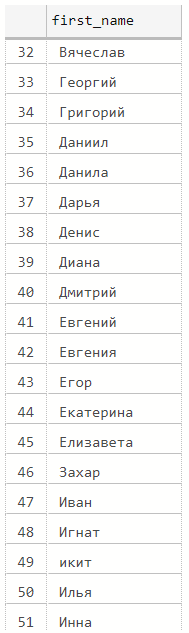
Сделаем подобные проверки для каждого поля. Подкорректируем формулы извлечения атрибутов для всех имеющихся проблем.
Заметим, помимо прочего, что у всех атрибутов могут быть пробелы как До, так и После их значения. Для их удаления будем применять ltrim(rtrim(value)).
Все это — data profiling и меры по очистке данных!
Похоже, что мы не можем исправить все возможные проблемы.
Высокий процент грязных данных после работы парсера говорит как о плохом качестве исходных данных, так и о плохой работе ETL-специалиста в части его подготовительной (исследовательской) работы перед написанием ETL.
Еще одна проблема – результаты заплывов (время). Строки не находятся в едином формате и, соответственно, не конвертируются в тип time(2).
Примеры значений в этом поле: ‘44.1’; ‘42,35’; ‘DSQ’; ‘1.09,98’, ’59’.
Среди значений времени присутствуют строки, дробная часть может отсутствовать, а может быть отделена от целой как точкой, так и запятой.
Будем разбивать значения этого исходного поля на два новых: результат-время и результат-дисквалификация. При этом само поле результат-время разложим на компоненты hh-mm-ss-ms с намерением впоследствии применить функцию timefromparts(hh, mm, ss, ms, precision) и тем самым сконвертировать результат из типа varchar к типу time(2).
In [1]:
declare @result varchar(100) = ''
--рекурсивная cte для разбиения строки-времени на отдельные составляющие-"тоукены"
;with cte_parse_time
as
(
select left(result, len(result) - patindex('%[:,.]%', reverse(result))) left_to_parse,
try_parse(right(result, patindex('%[:,.]%', reverse(result)) - 1) as int) token,
it = 1,
id
from (values(1, '44.1'), (2, '42,35'), (3, '1.09,98')) query(id, result)
union all
select iif(
patindex('%[:,.]%', reverse(left_to_parse)) <> 0,
left(left_to_parse, len(left_to_parse) - patindex('%[:,.]%', reverse(left_to_parse))),
'0') left_to_parse,
try_parse(iif(patindex('%[:,.]%', reverse(left_to_parse)) <> 0,
right(left_to_parse, patindex('%[:,.]%', reverse(left_to_parse)) - 1), left_to_parse) as int) token,
it = it + 1,
id
from cte_parse_time
where it < 4
)
select * from cte_parse_time
order by id, it
(12 rows affected)
Out[1]:
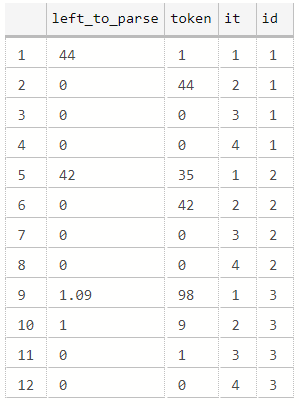
Теперь соберем все вместе.
Окончательный вариант:
In [3]:
use tempdb
;with cte_trim_fields
as
(
select ltrim(rtrim(F1)) as F1,
ltrim(rtrim(F2)) as F2,
ltrim(rtrim(F3)) as F3,
ltrim(rtrim(F4)) as F4,
ltrim(rtrim(F5)) as F5,
ltrim(rtrim(F6)) as F6,
ltrim(rtrim(F7)) as F7,
id
from dbo.stg_Competitions
),
cte_competition_info
as
(
select c.id,
c.F2 as competition_info,
rtrim(left(c.F2, charindex(',', c.F2) - 1)) as pool_city,
ltrim(right(c.F2, charindex(',', reverse(c.F2)) - 1)) as pool_description
from dbo.stg_Competitions c
join dbo.stg_Competitions c3 on c.id+4 = c3.id
where c3.F1 = '1' and (charindex('-', c.F2)<>0)
),
cte_list_of_competition_days
as
(
select c.id,
c.F2 as competition_day
from dbo.stg_Competitions c
join dbo.stg_Competitions c3 on c.id+3 = c3.id
where c3.F1 = '1' and (charindex('-', c.F2)<>0)
),
cte_list_of_group_discipline
as
(
select c.id,
c.F2 as group_discipline
from cte_trim_fields c
join cte_trim_fields c1 on c.id+1 = c1.id
join cte_trim_fields c2 on c.id+2 = c2.id
where (c1.F1 = '1' and (charindex('-', c.F2)<>0)) or
(c2.F1 = '1' and (charindex('-', c.F2)<>0))
),
cte_list_of_ranges_competition_days
as
(
select piv.start_id, isnull(end_id, num.cnt) end_id
from
(
select id start_id,
lead(id) over(order by id) end_id
from cte_list_of_competition_days
) piv
cross join (select count(1) cnt from dbo.stg_Competitions) num
),
cte_list_of_ranges_discipline
as
(
select piv.start_id, isnull(end_id, num.cnt) end_id
from
(
select id start_id,
lead(id) over(order by id) end_id
from cte_list_of_group_discipline
) piv
cross join (select count(1) cnt from dbo.stg_Competitions) num
),
cte_pivot
as
(
select c.*,
gd.group_discipline,
cd.competition_day,
--ci.competition_info,
ci.pool_city,
ci.pool_description
from cte_trim_fields c
join cte_list_of_ranges_discipline rd on c.id between rd.start_id and rd.end_id-1
join cte_list_of_group_discipline gd on gd.id = rd.start_id
join cte_list_of_ranges_competition_days rcd on c.id between rcd.start_id and rcd.end_id-1
join cte_list_of_competition_days cd on cd.id = rcd.start_id
cross join cte_competition_info ci
),
cte_transform
as
(
select
F1 as place,
iif(charindex(' ', F2)<>0, left(F2, charindex(' ', F2) - 1), F2) as last_name,
iif(charindex(' ', F2)<>0, right(F2, len(F2) - charindex(' ', F2)), null) as first_name,
iif(len(F3)=2, iif(left(F3, 1) in ('8','9'), '19'+F3,'20'+F3), F3) as birth_year,
iif(charindex(',', F4)<>0, left(F4, charindex(',', F4) - 1), F4) as city,
iif(charindex(',', F4)<>0, right(F4, len(F4) - charindex(',', F4)), null) as team,
F5 as country,
iif(charindex('D', F6)=0, iif(len(F6)=2, F6+'.00', F6), null) as result,
iif(charindex('D', F6)<>0, F6, null) as disc,
F7 as points,
rtrim(left(group_discipline, len(group_discipline) - charindex('-', reverse(group_discipline)))) as athlete_group,
ltrim(right(group_discipline, charindex('-', reverse(group_discipline)) - 1)) as discipline,
ltrim(right(competition_day, len(competition_day) - charindex('-', competition_day))) as [date],
pool_city,
pool_description,
id
from cte_pivot
where F1 is not null
),
cte_parse_time
as
(
select left(result, len(result) - patindex('%[:,.]%', reverse(result))) left_to_parse,
try_parse(right(result, patindex('%[:,.]%', reverse(result)) - 1) as int) token,
it = 1,
id
from cte_transform
union all
select iif(patindex('%[:,.]%', reverse(left_to_parse)) <> 0, left(left_to_parse, len(left_to_parse) - patindex('%[:,.]%', reverse(left_to_parse))), '0') left_to_parse,
try_parse(iif(patindex('%[:,.]%', reverse(left_to_parse)) <> 0, right(left_to_parse, patindex('%[:,.]%', reverse(left_to_parse)) - 1), left_to_parse) as int) token,
it = it + 1,
id
from cte_parse_time
where it < 4
),
cte_clean_and_format
as
(
select try_parse(place as int) place,
left(last_name, len(last_name) - charindex(' ', reverse(last_name))) last_name,
left(first_name, len(first_name) - charindex(' ', reverse(first_name))) first_name,
try_parse(birth_year as int) birth_year,
city,
replace(replace(team, '"', ''), '''', '') team,
country,
timefromparts(h.token, m.token, s.token, ms.token, 2) result,
disc,
try_parse(points as int) points,
athlete_group,
try_parse(left(discipline, charindex(' ', discipline)) as int) distance,
right(discipline, len(discipline) - charindex(' ', discipline) ) as style,
try_convert(date, [date], 104) [date],
pool_city,
pool_description,
t.id
from cte_transform t
join cte_parse_time h on t.id = h.id and h.it = 4
join cte_parse_time m on t.id = m.id and m.it = 3
join cte_parse_time s on t.id = s.id and s.it = 2
join cte_parse_time ms on t.id = ms.id and ms.it = 1
)
select top 2 * from cte_clean_and_format
(2 rows affected)
Out[3]:
В будущем, запрос выше можно оформить в хранимую процедуру или табличную функцию и использовать как отдельный компонент в «большом» ETL-процессе.
Используя язык SQL, мы создали основу ELT-процесса парсинга полуструктурированных данных.
Заметим, что код выше не является идеальным. Это скорее R&D-решение, полученное дата-аналитиком в процессе исследования исходных данных. Вопрос оптимизации будет решен дата-инженером во время создания полноценного ETL-процесса.
* Материалы, использованные в статье (код, исходный Excel-файл, результаты работы парсера, выгруженные в csv-файл) можно получить по этой ссылке.
Автор материала – Тимофей Гавриленко, преподаватель Тренинг-центра ISsoft.

Образование: окончил с отличием математический факультет Гомельского Государственного Университета им. Франциска Скорины.
Microsoft Certified Professional (70-464, 70-465).
Работа: c 2011 года работает в компании ISsoft (ETL/BI Developer, Release Manager, Data Analyst/Architect, SQL Training Manager), на протяжении 10 лет до этого выступал как Sysadmin, DBA, Software Engineer.
В свободное время ведет бесплатные образовательные курсы для детей и взрослых, желающих повысить свой уровень компьютерной грамотности и переквалифицироваться в IT-специалиста.






