
Опыт показывает, что абсолютное большинство разработчиков начального уровня, равно и тех, кто не специализируется на базах данных, допускает серию типичных ошибок и “ляпов”, создавая SQL-скрипты.
В этой статье мы рассмотрим лучшие устоявшиеся практики в отношении того, как создавать и оформлять DDL-скрипты для создания таблиц и ограничений.
Логическая модель данных:
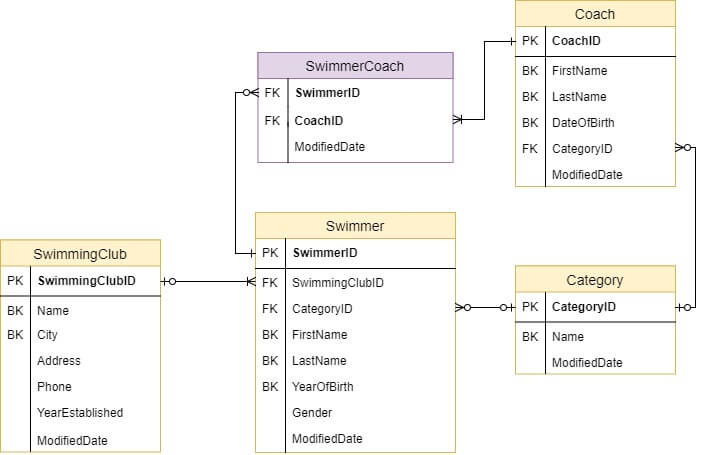
Пример «плохого» DDL-кода:
In [1]:
create table Category (
CategoryID int identity primary key,
Name nvarchar(20) not null UNIQUE,
ModifiedDate date not null
)
create table SwimmingClub (
SwimmingClubID int identity primary key,
Name varchar(50) not null,
City varchar(50) not null,
Address varchar(50) not NULL,
Phone varchar(50) not null,
YearEstablished int not null,
ModifiedDate date not NULL
)
create table Swimmer (
SwimmerID int identity primary key,
SwimmingClubID int not null,
CategoryId int not null references Category(CategoryId),
FirstName varchar(50) not null,
LastName varchar(50) not null,
YearOfBirth int not NULL,
Gender int not null,
ModifiedDate date not NULL
)
create table Coach (
CoachID int identity primary key,
FirstName varchar(50) not null,
LastName varchar(50) not null,
DateOfBirth date not NULL,
CategoryID int not null references Category(CategoryID),
ModifiedDate date not NULL
)
create table SwimmerCoach (
SwimmerID int not null references Swimmer(SwimmerID),
CoachID int not null references Coach(CoachID),
ModifiedDate date not NULL
)
go
Код выше “плохой” по ряду причин:
- Он содержит код всех таблиц и ограничений одним “комком”.
Как следствие:
- нескольким разработчикам тяжело работать над этим файлом одновременно (возможны merge-конфликты при сохранении результатов в SVC либо вместо распараллеливания разработку придется сериализовать);
- при изменении любой части кода нужно проводить заново тестирование всех объектов, перечисленных в файле;
- порядок создания сущностей и констрейнтов имеет значение, то есть при сбое в создании одного объекта “посыпятся” другие; при рефакторинге модели данных нужно думать о порядке выполнения новых фрагментов кода.
2. Таблицы создаются сразу с ограничениями (зачастую с анонимными), которые тяжело рефакторить или удалять. Проблемы появятся, когда мы захотим создать БД без ограничений или создать последние только после импорта данных.
3. Не соблюдены соглашения об именовании объектов и не выдержан единый стиль. Код трудно читать:
- регистр букв и ключевых слов “пляшет”;
- отступы и название схемы перед именем объекта отсутствуют;
- многие ограничения создаются неявно, без присвоения им имени (что может позже стать проблемой при необходимости изменить или удалить ограничение).
4. Имена идентификаторов, совпадающие с ключевыми словами языка SQL не экранированы.
5. Судя по косвенным признакам (например, часто повторяющимся типам varchar(50)) предварительный data-profiling не произведен.
6. Нет проверок на существование объектов перед их созданием
и прочее …
«Хороший» DDL-код подразумевает:
- следование определенным naming conventions и code style (а значит, читаемость);
- готовность к последующему рефакторингу;
- готовность к миграции на другие СУБД или к downgrade текущей;
- воспроизводимость результатов при перезапуске;
- возможность легкого и гибкого разворачивания;
- …
Посмотрим, к примеру, как можно было оформить DDL скрипт для создания таблицы dbo.Category (/SQL/code/DDL/tempdb — DDL — table — dbo.Category.sql):
In [2]:
--выбираем активную БД
use tempdb
go
--создаем объект, предварительно проверяя был ли он создан ранее
--стараемся использовать "классический" подход
--drop table if exists #Category
if OBJECT_ID('dbo.Category', 'U') is not null
drop table dbo.Category
go
create table dbo.Category
(
CategoryID tinyint not null identity,
[Name] nvarchar(20) not null,
ModifiedDate datetime not null,
constraint PK_Category primary key (
CategoryID
)
)
go
Обратите внимание, в приведенном выше примере мы создаем объект, предварительно проверяя существует ли он уже, используя для этого классический для SQL Server подход. Эту же операцию можно было выполнить используя новый синтаксис drop table if exists, но последний вариант не будет работать на старых версиях СУБД (ситуация когда версия dev-сервера не совпадает с версией production-сервера, версии локальных dev-серверов для разных разработчиков не совпадают между собой или нужно выполнить downgrade не так уж и редка).
Возможно, еще лучшим вариантом для проверки наличия таблицы было бы использование INFORMATION_SCHEMA.TABLES, что работает не только в разных версиях SQL Server, но и легко переносится на другие версии реляционных СУБД, поддерживающих ANSI-стандарт.
Основной ключ таблицы создаем вместе с самой таблицей, так как его наличие – это требования первой нормальной формы и, в отличие от остальных, это ограничение действительно важное.
Файл с DDL-кодом для ограничений (/SQL/code/DDL/tempdb – DDL – constraint — dbo.Category.sql):
In [3]:
--выбираем активную БД
use tempdb
go
--удаляем констрейнт если он был создан ранее
--AK_Category_Name
if exists(select 1 from INFORMATION_SCHEMA.TABLE_CONSTRAINTS where CONSTRAINT_NAME = 'AK_Category_Name')
alter table dbo.Category drop constraint AK_Category_Name
go
alter table dbo.Category add constraint AK_Category_Name unique
(
[Name]
)
go
--Альтернативный способ проверки существования ограничения: DF_Category_ModifiedDate.
--if exists(select 1 from INFORMATION_SCHEMA.TABLE_CONSTRAINTS where CONSTRAINT_NAME = 'DF_Category_ModifiedDate')
if OBJECT_ID('DF_Category_ModifiedDate', 'D') is not null
alter table dbo.Category drop constraint DF_Category_ModifiedDate
go
alter table dbo.Category add constraint DF_Category_ModifiedDate default GETDATE() for ModifiedDate
go
Обратите внимание, имена всех ограничений соответствуют четкому правилу <префикс>_<имя таблицы>_<имена полей>.
В мире баз данных приняты такие префиксы:
DF – default, значение по умолчанию;
IX – index, некластерный, неуникальный индекс;
UC или AK – unique constraint, alternate key, альтернативный ключ, уникальный индекс;
PK – primary key, основной ключ;
FK – foreign key, внешний ключ.
В этом случае правило именования ограничения немного иное: FK_<имя первой таблицы>_<имя второй таблицы>
Разделение DDL кода отдельно на таблицы и ограничения имеет смысл при деплойменте и рефакторинге.
Деплоймент в этом случае легко осуществить, выполнив сначала в
любой последовательности все скрипты на создание таблиц, а потом все скрипты на
создание ограничений (опять же, в любой последовательности).
Если не делать это разделение, во время релиза нужно думать о порядке выполнения
скриптов (так как внешние ключи требуют уже существующей таблицы, на которую
ключ ссылается).
Рефакторинг отдельных мелких скриптов можно выполнять в параллели (в отличие от работы над единым большим скриптом).
Плюс, несколько измененных мелких скриптов требуют ограниченного тестирования, в то время как один измененный большой скрипт требует полного ретеста.
Все скрипты DDL данного учебного проекта находятся здесь: https://github.com/timoti1/T-SQL
Обратите внимание также на именование файлов и структуру папок репозитория. Тут тоже должно работать некоторое соглашение об именовании объектов, не позволяющее репозиторию превращаться в свалку мусора, когда непонятно что где лежит и какие файлы за что отвечают.
Вывод.
Код чаще читается чем пишется и, зачастую, его пишет один человек, а читают многие! Порой кроме кода нет никакой иной документации.
Уделяйте внимание тому насколько надежен, насколько понятен другим и как выглядит продукт вашего труда. Более того, создавайте код, который легко деплоить, переносить на другой сервер, тестировать и редактировать одновременно нескольким разработчикам!
Автор материала – Тимофей Гавриленко, преподаватель Тренинг центра ISsoft.

Образование: окончил с отличием математический факультет Гомельского Государственного Университета им. Франциска Скорины.
Microsoft Certified Professional (70-464, 70-465).
Работа: c 2011 года работает в компании ISsoft (ETL/BI Developer, Release Manager, Data Analyst/Architect, SQL Training Manager), на протяжении 10 лет до этого выступал как Sysadmin, DBA, Software Engineer.
В свободное время ведет бесплатные образовательные курсы для детей и взрослых, желающих повысить свой уровень компьютерной грамотности и переквалифицироваться в IT-специалиста.






